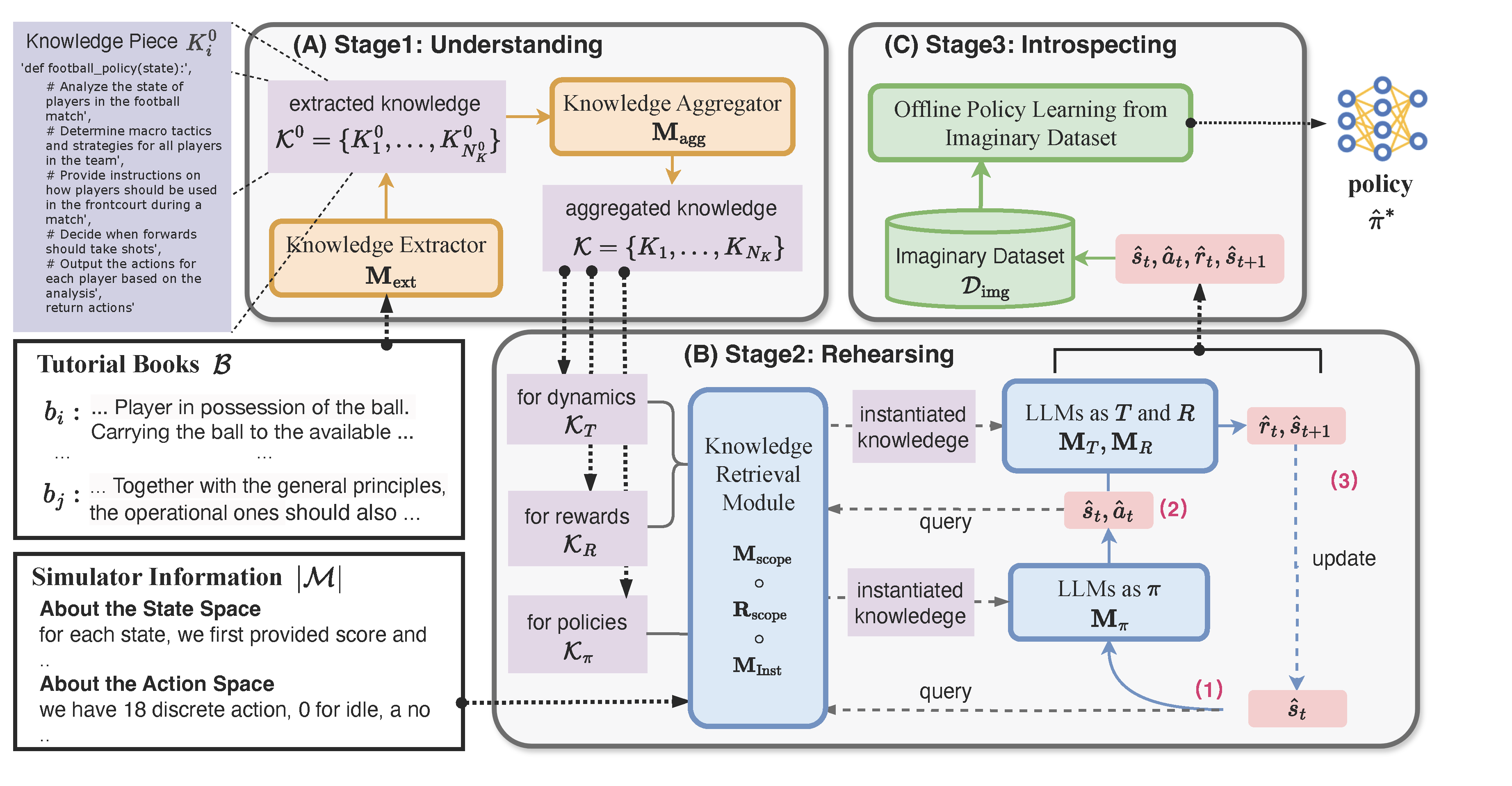
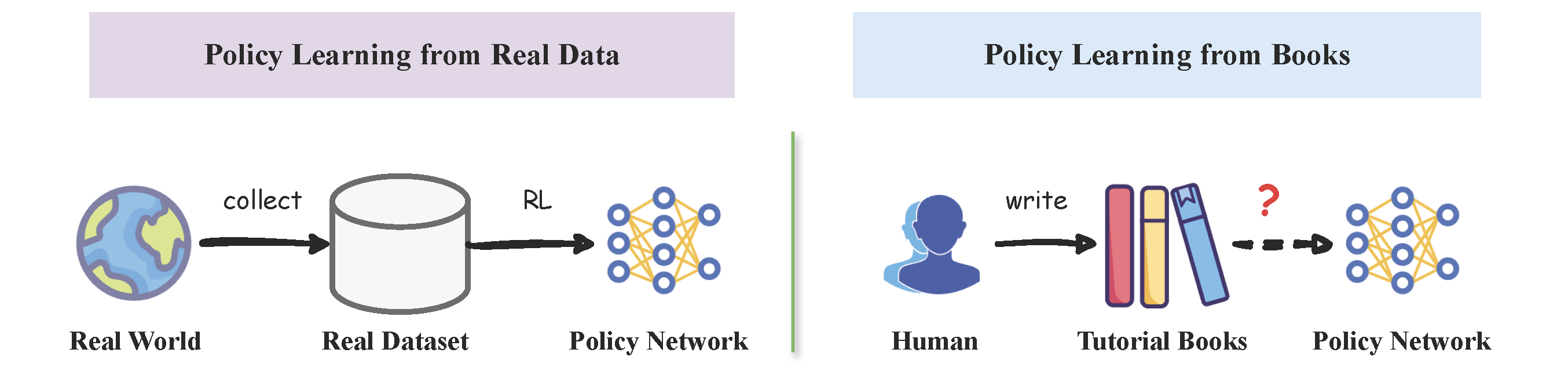
When humans need to learn a new skill, we can acquire knowledge through written books, including textbooks, tutorials, etc. However, current research for decision-making, like reinforcement learning (RL), has primarily required numerous real interactions with the target environment to learn a skill, while failing to utilize the existing knowledge already summarized in the text. The success of Large Language Models (LLMs) sheds light on utilizing such knowledge behind the books. In this paper, we discuss a new policy learning problem called Policy Learning from tutorial Books (PLfB) upon the shoulders of LLMs’ systems, which aims to leverage rich resources such as tutorial books to derive a policy network. Inspired by how humans learn from books, we solve the problem via a three-stage framework: Understanding, Rehearsing, and Introspecting (URI). In particular, it first rehearses decision-making trajectories based on the derived knowledge after understanding the books, then introspects in the imaginary dataset to distill a policy network. We build two benchmarks for PLfB~based on Tic-Tac-Toe and Football games. In experiment, URI's policy achieves at least 44% net win rate against GPT-based agents without any real data; In Football game, which is a complex scenario, URI's policy beat the built-in AIs with a 37% while using GPT-based agent can only achieve a 6\% winning rate.
.png)